
Enhancing the Common Operating Picture with Digital Twins
Read time: 20-30min
In this article, we share our views on potential ways to improve Situation Awareness (SA) across industrial organisations.
We break down some requirements of creating high individual and shared SA, and the subsequent features that aid in creating and regaining SA.

The purpose of this article is to create greater awareness of the depths of the SA challenge, and to explain the rationale behind our current research and design efforts. Our “Situation Twin” is nearing release and we will be providing more details on the solution we propose to the challenges discussed below.
Introduction
In today's complex industrial environments, high situation awareness is more critical than ever. High situation awareness enables high quality decisions and reduces the probability of low quality decisions. In high risk industries such as mining, a Common Operating Picture (COP) has long been a desire for ensuring that all team members are aligned and armed with the information they need to make decisions. The proliferation of Remote Operating Centres (ROCs/IROCs/IOCs/VOCs/NOCs/xOCs) is reviving the debate on how best to create a COP, what a COP should really “be”, and can we utilise COPs beyond the traditional emergency response or incident management situation.
Outside of xOCs, data availability is stirring discussion that all workers should have access to a COP, because data is now ubiquitous. The reality though often falls short of the desire, and the explosion of siloed IT and OT systems has led to an explosion of unique dashboards and multiplication of viewpoints. The result is hundreds of bespoke dashboards, driven by organisational silos, and connected to siloed data sources. The very ease of PowerBI and Tableau have created a conflation between a “common reporting tool” and a “common operating picture”. Similarly, the data lake as the “source of truth” misidentifies that the provenance of data does not create the commonality or context users desire – the Common in COP refers to a shared understanding, and the Picture is the context of the situation to which that understanding is applied.
A shared understanding of the operating context is a much better, though less pithy description for COP.
What does it take to create a “good” COP?
In this paper we explore how elevating individual situational awareness, creating context based on goals, and enabling discovery of information fuel a virtuous cycle that enhances individual understanding of the operating context. Individuals must then collaborate with team members and stakeholders to jointly discover and project courses of action. Only when more than one user has enhanced their shared situation awareness can we say that a Common Operating Picture has been achieved. We also show that there can be many COPs in an organisation and that the user and their goal is the fundamental building block of COPs. We show that digital twins are an ideal platform for creating COPs and connecting them to action in the real world.
COP, SA and Twins
Let’s level set first.
The COP is the Common Operating Picture, a software solution that provides a continuously updated environmental representation designed to provide a comprehensive and shared situation awareness for all levels of an organisation. It is generated by the real-time integration of data from multiple sources and domains, allowing for a unified view that supports timely decision-making. The COP creates a shared understanding of the operating context for users of the system.
Situation Awareness (SA) is the perception of environmental elements within a volume of time and space, the comprehension of their meaning, and the projection of this meaning into the future. We are constantly “situating” ourselves, and our ability to perceive, comprehend and project determines our awareness of the situation.
Decisions follow Situation Awareness. When we have “situated” ourselves and projected what we think will happen, we make decisions. “Good” decisions are usually founded on “good” SA, because we understand the situation and have correctly projected what will happen, and our decision aligns to or creates that projected future reality. Incorrect, incomplete and disrupted SA often precede poor decisions. Actions follow Decisions. In “fight or flight” situations, SA can become very narrow, and decision and action can occur almost simultaneously. These special situations are not relevant to a discussion of “good” decisions, except to say that helping people to maintain and regain SA quickly is beneficial in all decision making circumstances.

The Twin is a Digital Twin, a software solution that comprises a virtual representation of a selected portion of the real world, with two-way interconnections, synchronised at specified frequencies and fidelities, and designed to create change in the physical that can be measured and improved in the virtual. The Twin is designed to enable users to create and measure change in the real world.

Individual situation awareness
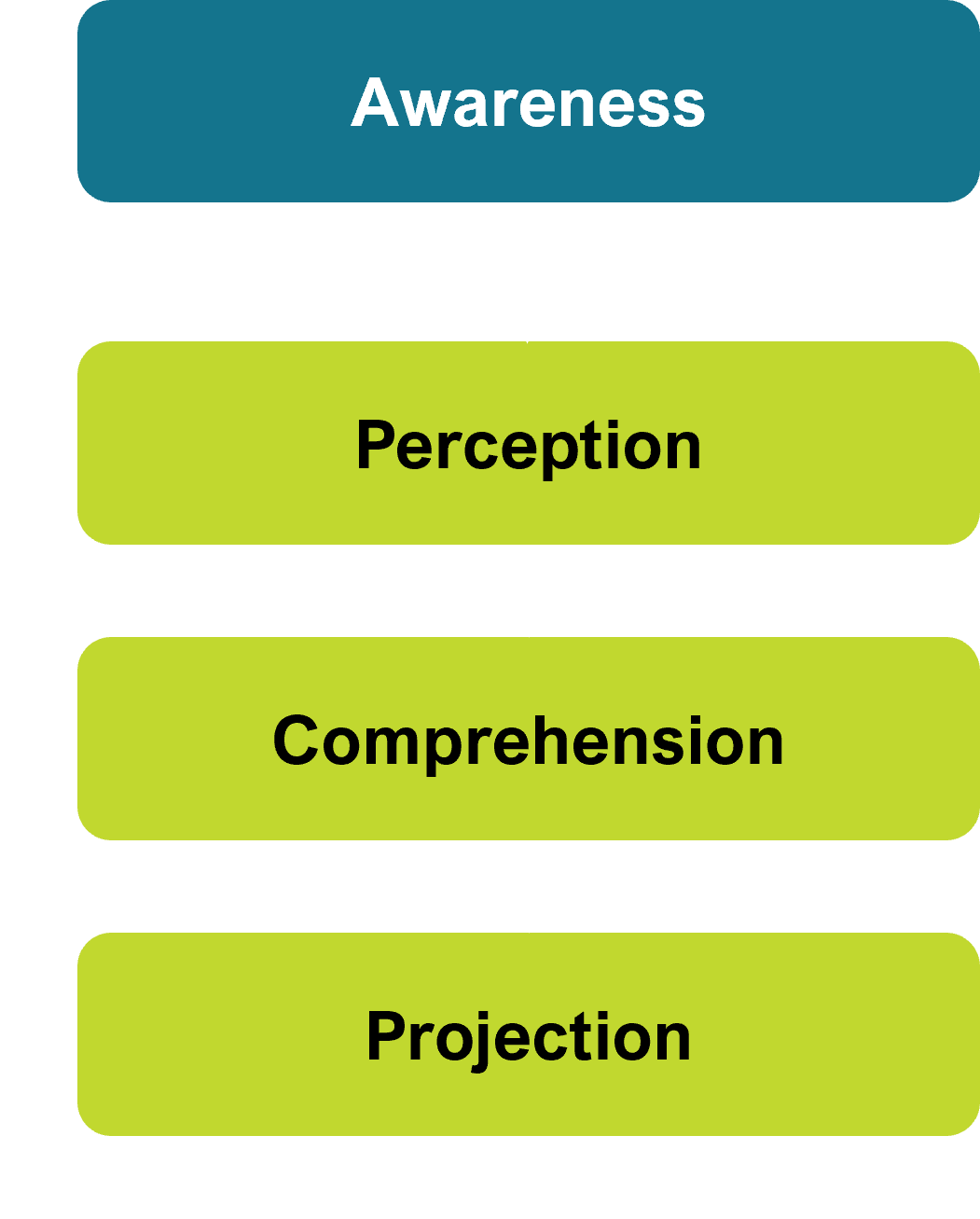
The formal definition of Situation Awareness (SA) is broken down into 3 levels:
Perception (of the elements of the situation)
Comprehension (of the current situation)
Projection (of future status)
The first level of SA is noticing the elements of the situation you are observing.
What is perceived can be comprehended, but often when we “see” something we only perceive a portion of what is going on. Attention, time span, rate of change, ease of viewing and the limitations of the human body (e.g. we typically cannot see heat, but if close enough we can feel it) all impact our perception.
The second level of SA is figuring out what the perceived information means in relation to the current situation and goals.
The impact of goals on comprehension cannot be overstated – information is comprehended in relation to desired future states. The desire to see “everything” is a misnomer because this implies all possible paths and consequences are being considered. Similarly, information that is perceived may not be comprehended correctly. A good example is some types of pilot error. The pilot may see the altitude as 10,000 feet but fail to realise local terrain is up to 12,000 feet or fail to comprehend that the order from air traffic control to move to 9,000 feet requires action. Perception does not equal comprehension, and overload of perception reduces comprehension. Stated another way, more data is better until a point where it is suddenly worse. Domain expertise also impacts comprehension; experience combines multiple data points into a single comprehended whole, quickly.
In some cases however, expertise leads to creating a pattern from data that is perceived as fitting what the experienced person believes is happening. “Jumping to conclusions” is effected by what information is perceived, what order it appears in, and the cognitive impact of too much data. When we see 10 things, and 5 fit a pattern, we often key in on the pattern very quickly and de-rate the information that doesn’t fit.
The third level of SA is projecting what the perceived and comprehended elements of the situation will do in the future.
This is where domain expertise has a major impact. Having a highly developed mental model allows the decision maker to respond very quickly to recognised patterns, and project what the elements of the situation will (likely) do. This presents as the comprehended (current) pattern transforming into a new future pattern.
How does SA really work?
These 3 levels of SA are not linear.
We are constantly perceiving (and not-perceiving and mis-perceiving), comprehending (and not-comprehending) and projecting what we think will happen. Humans are great at fusing data from all our senses in real time to situate ourselves. Unfortunately, much of this capability is evolved to protect ourselves from immediate threats in our immediate environment. Why is this unfortunate? Because where we are decoupled from the environment (e.g. through a screen) and where most of our senses are no longer used (we perceive primarily with the eyes now), and where most issues are not real time and threatening (and therefore we don’t need to project immediate patterns of the most threatening elements), our biological equipment is sub-optimal for the kinds of problems we are seeking to solve. Good for lions, less good for economic tradeoffs.
The other major challenge is that these highly developed mental models live in our head.
The more experienced you are in a domain, the more developed your mental model. The maintenance superintendent who has worked at the same mine for 15 years has an extremely well developed mental model for where everything is (that is of interest to her) and how the elements of the environment fit together, including many non-structured data points such as how particular equipment sounds when it has a problem. This model enables extremely rapid and accurate comprehension and projection of problems and immediate problem solving ideation, based on available capabilities. The experienced maintainer knows what is wrong and what needs to be done and has a fair idea of what can be done.
The problem arises in 3 areas
Firstly, it is very difficult to obtain this knowledge.
It requires years or decades of direct perception-comprehension-projection and measurement of the accuracy of these thoughts, making this knowledge extremely difficult to pass on. You can’t learn this mental model by watching a video. You can learn what to do in a certain situation, but you can’t learn what the elements of the situation were that created the current situation. Not being able to project makes it very difficult to “reverse engineer”, which in turn implies a poor SA. SA connects outcomes to thoughts, which creates mental models.
Secondly, the expert model is mostly built on data she has directly perceived, plus data received via secondary channels.
The model is strong where it has been trained. For an operator on site, the reinforcement of direct experience is far greater than the ingestion of written analysis. For the data scientist, the reinforcement of analysis is far greater than the ingestion of dust on a quarterly site visit. We are what we eat, and when a new food comes along that may be better for us, it doesn’t mean we’re going to eat it and even if we do, it’s not going to change us overnight. If 100 new data models appear on site, all superior to one aspect of one individuals maintenance model, the maintenance superintendent will still mainly rely on the expert trained model. It’s coherent, it’s not easily divisible, and it provides exceptional SA when fed with the information it was trained on. Data from outside the model is harder to comprehend and creates uncertainty in projection, and thus is often discounted. This presents when the expert is faced with data that is mutually contradictory, or data outside the range the model was trained on, or new data that is not part of the model but is critical. The experts model becomes far less valuable, the perceive-comprehend-project cycle becomes much harder and a greater cognitive burden, and the expert must fight the natural pull of incorrect but well known patterns. Expert airline pilots with thousands of hours of experience on a specific aircraft can be overwhelmed by 3 or 4 data points that cannot be aligned with their mental model. Running out of time in many other situations does not have as dramatic an outcome, but suboptimal outcomes from individual models due to misalignment with reality are common.
Lastly, the model is stuck in her head.
It cannot be shared, and using words to explain it generally results in a poor outcome. The model is multi-dimensional, holistic, and effectively “unexplainable”. The brain is the original black box, perpetually recording but without a good API. We know we cannot convey more than a fraction of our model to others, so we don’t ask the question “can you please teach me everything you know about maintenance?". When same domain experts meet, sparks can fly as the same information that is perceived is comprehended and projected in a different way. Same data type, different model, different comprehension. When experts from different domains meet, comprehension sparks rarely fly because they are weighing different data very differently. Frequently they talk past each other, each trying to explain the tiny sliver of their model that is associated with the specific data that is critical to their model. They typically skip shared comprehension because there’s so little overlap in models and jump to projection (where the sparks fly). Explaining why a decision was made can be very difficult. Explaining why in a culture of blame further increases the cognitive burden. Stress inhibits decision making, and it does so by reducing situation awareness.
Situation awareness is hard won, built on direct experience, difficult to adjust and unexplainable. It is extremely valuable to the individual and is why we place such an emphasis on experience; for the many areas where we do not have data driven models to make decisions, high situation awareness is essential to good decision making, but is only achievable with domain expertise and when fed with data that aligns to the model and is within acceptable ranges.
How can SA be increased?
Increasing SA for decision makers has positive impacts.
People make “better” decisions, which often means they make less mistakes, or the outcomes of decisions have fewer negative impacts. Increasing SA, especially for decision makers who are remote from the situation, primarily revolves around ensuring that the systems the decision maker use enable and promote “high” SA. As we will see, increasing SA is based on helping the decision maker increase their own SA. We can’t “give” SA but we can help decision makers increase their SA.
Given that we are focused on remote decision makers, and the establishment of a COP, we shall refer to the decision maker as the user. They use COPs to make decisions on situations that may or may not be remote from themselves. Before we leap to solutionising, let’s explore how SA is increased. We are still in the problem definition stage. When we begin the solution, these elements will inform our methods of solving. The 3 critical elements we will discuss are:

Firstly, it’s important to understand that SA is goal seeking.
We do it consciously and sub-consciously, sometimes iterating and leaping back and forth very quickly, in order to understand better what is happening. The “situation” in SA can be misleading; we are not trying to understand the minutiae of a situation, we are trying to understand the situation in order to better project what this situation means. That projection must have a direction. It’s a vector, not a scalar. And the direction is the goals we have, conscious or otherwise. We’ve often been told that we must set clear goals, and here’s one of the reasons why: we interpret the present through our view of how it supports our projection of the future. Similarly, we interpret the present though our view of how the past created it. If the present doesn’t fit our view of the future, we often alter our view of what is happening now. If the present doesn’t fit our view of the past, we often alter our view of what happened then. We bias towards information that fits our mental model, rather than altering our mental model based on different data. This is especially true when our goals are unclear.
If you are worried about your weight (situation based), you are unlikely to start a new exercise regime. Even if you do a few sessions (tasks), you are much more likely to stop doing those tasks without a clear goal. If you have a goal to run 5km without stopping before Christmas (goal directed), you’re very likely to start a new exercise regime, which will involve new tasks. Goals create direction for your projection, which influences your comprehension which influences your perception. You see more and understand better what supports your projection of a desired future. You don’t see cigarettes as cancer sticks, because you don’t have a goal of “getting cancer”. Because it’s not your goal, your projection doesn’t include you getting cancer, and your comprehension of the risks is that they are low, and you bias your perception of what you hear more towards data that supports your projection… it’s a funny old box we walk around in. The business related point is, goals influence SA much more than tasks. “Good” SA is not focusing on the tasks we need to do, it’s focused on the goals we need to achieve. Creating the conditions for good SA requires goal direction.
Similarly, detailed and rigid plans can undermine SA.
Adhering to pre-planned tasks while the situation is changing creates poor SA. Executing the planned tasks may or may not create poor outcomes. The impact of the situation on the tasks may be non-causal, especially if the situational data is fixed and siloed, and the task is driven by or owned by another silo. Stopping this article to answer a question from my wife has no significant consequences (I was waffling anyway). Proceeding with the planned isolation a day before a shut down is an opportunity cost. Sending a graduate out to a remote dam to do a water quality test during a violent storm is a risk. Changing plans because of changing conditions is not a failure of planning, it’s SA. Goals that are formed as a part of plans direct SA; when conditions change outside of the plan, we must know that they have changed or else we cannot improve our SA. This leads to the concept of Visibility.
Visibility of data that is associated with achieving the goal or that impacts the goal is paramount. If the user cannot “see” the data (and remember that sight is only one sense, but it is the primary one for a remote user) that informs their SA, then they cannot improve their SA. If the data is siloed by the users department, then it is very unlikely to include data that impacts the goal but is not task required. In other words, non-task data that impacts the goal is required to inform decisions on the tasks. The non-task data that may be required is determined by the goals. We say may be, because not all data that is related to a goal is required to for any one task. For some non-task data, it only needs to be visible if it will or may effect the goal. Confused? Good, you’re getting it.
Let’s pull back the curtain on what this means and how we handle it.
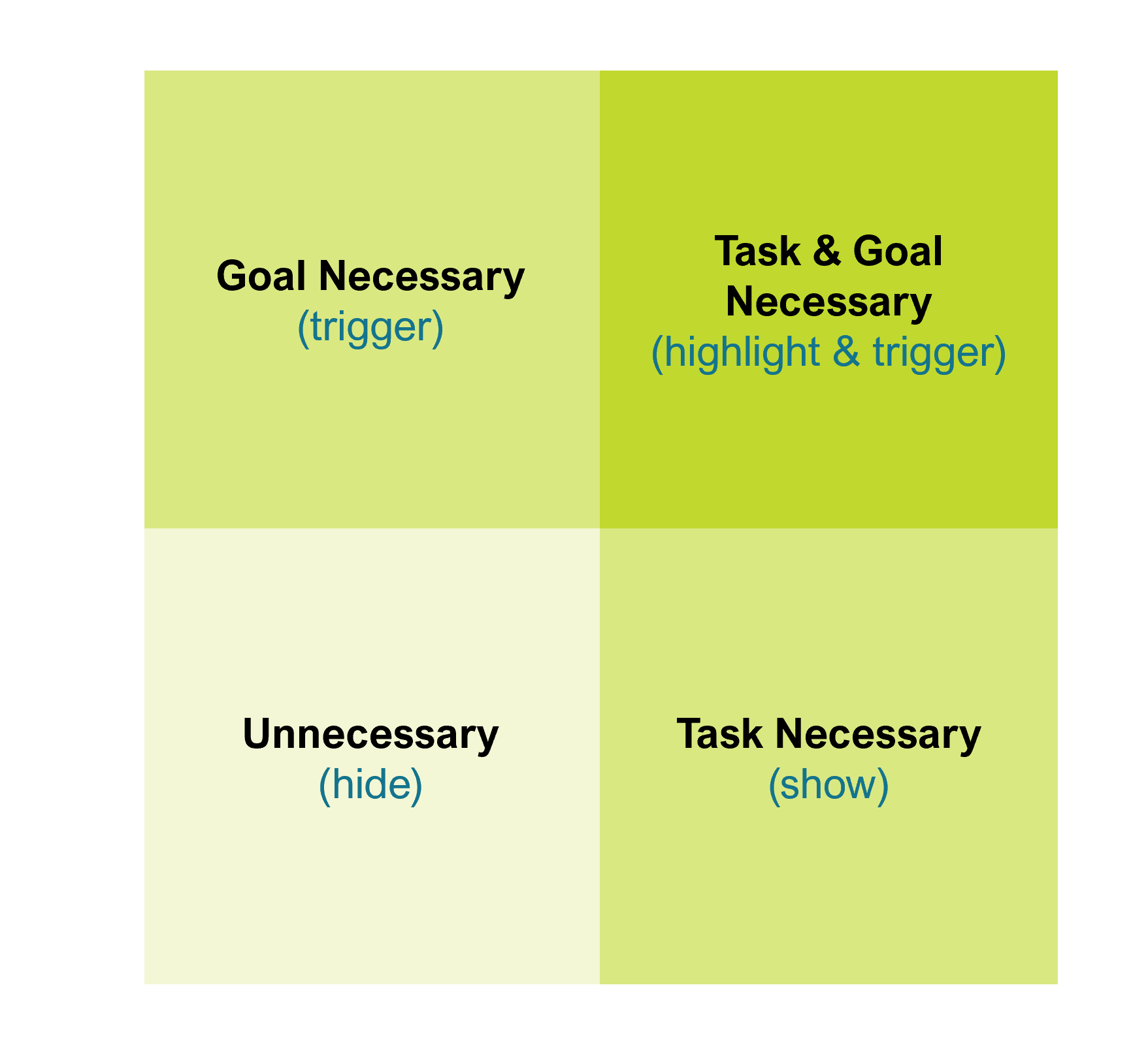
Data that is required for Tasks and impacts Goals is the most critical.
It needs to be highly visible, and also have triggers on it. It’s not enough to just show it, we must highlight that not only is it required for a task, but it impacts our goals. Data that is required for a Task needs to be shown. We want task completion to be easy, and data that is difficult to find reduces efficiency. Data that could impact goals but is not task related should be hidden to reduce cognitive load. Hidden doesn’t mean absent; if it is triggered, it needs to become Visible and “interrupt” the SA cycle. Lastly data that is neither task nor goal focused is ideally hidden to reduce cognitive load. More data isn’t better, until you need it.
As mentioned previously, situations change. In fact the main reason we need SA is because situations change. Static conditions can be learned quickly, and a strong mental model formed. Ironically, SA can be hard to maintain because users get bored and distracted easily. The watched pot often boils over because the watcher was looking at their phone. Triggers and notifications go a long way to helping this “null” case, though a non-human user is far superior; create the mechanism that never sleeps, but make sure it knows what it’s watching. In all other cases though, SA iterates as the situation changes. We’ve shown that goal seeking informs the direction of projection, but we also know that people “leap” to data and make seemingly non-causal connections. In both cases, users are exploring to find additional data to enhance their SA, though they may not be able to explain why they they are exploring in a particular direction.
Software designers spend considerable time trying to guess the flow of users through a system, trying to forecast where they’ll go and what they’ll do next, usually based on workflows or frequency of use. The ability to find what you want, when you want it, contributes heavily to the user experience. We’ve all had rage strokes trying to find the right table buried 13 layers down in SAP, and we’ve all been baffled by an app with seemingly no options to address the issue we have at all (“it’s a very clean UI…”). On a spectrum we have highly prescribed workflow engines at one end, and search engines at the other. One is rigidly constraining the user, the other is ready to pounce in any direction the user directs. To improve SA, we must improve visibility. To improve visibility, we must / should (must? should!) enable exploration to gather more data, because the situation will change.
For algorithmic based decision makers, the algorithm can only ingest data that it is fed, and this data must align to the algorithm to have any impact on the outcome. Sparse, sporadic or volatile data can result in radically different outcomes over different time periods, and data that is not captured or does not align to the algorithm has no impact on the algorithmic outcome (but may have huge impacts in the real world). Humans ingest many data points (if and only if the data is perceived - we don’t ingest much when asleep or distracted) and fuse with experience and emotion to create novel, often non-repeatable decisions, while machines ingest all data that is correctly formatted and used in the singular algorithm. Where machines learn, the algorithm can be biased and factored to improve the outcome (as measured against objectives) over time, but extraneous and spurious data is still ignored. For a human, “spurious data” may be the context that enables 2nd or 3rd order connections to provide context to validated data. We also “jump” to other ideas, based on pattern matching, that aren’t seemingly causally associated or supported by presented data, and we project the impact of the “jump idea”, assess validity/risk/fear and loop back to what we perceive. Fear of the future absolutely impacts what we perceive, not just comprehend. There are fast and concurrent loops, and when the pressure is on, the loop velocity increases, though sometimes cycling through the same pattern. People get “stuck” in a loop and it presents as paralysis. Humans jump to ideas when triggered, and experience, emotion and data can apply rapidly varying weightings to our decisions.
This “creativity” that humans possess and machine seeks to replicate, is often founded upon contextual data that triggers experience, which in turns triggers information discovery to validate or invalidate the experiential feeling. The ability to discover information related to a trigger is critical and an expected part of any technical and professional worker. At mine sites and other heavy industrial industries, we do not have untrained workers, nor do we have workers who need to make critical decisions without associated workflows or multiple levels of governance. Similarly for machine decisions, design and testing is completed before any machine decision maker is considered production ready. We expect our decision makers to check if they’re unsure, and to dig deeper or wider if they want to know more.
Thus all (critical) industrial decision making entities have guidance on how to make decisions of certain types. All experienced human decision makers know that the business process, however complex and governed it may be, only captures the specific elements that must be completed or checked. The “bits in between” can be frequent occurrences for most, and these bits are usually not captured in structured systems and cannot be captured with intermixed manual and digital process steps across multiple systems. Structured processes are therefore full of gaps that humans fill in, and these gaps are where we explore for more data or use our mental model to fill in the bit we already know. Even the most rigid of tasks involves discovering additional information when the situation changes.
Exploration of other information is therefore a crucial part of maintaining SA as the situation changes, and the situation is changing even across well established business processes. SA is disrupted the most when the situation changes around a business process, and the cognitive dissonance of goal impact vs task impact shouldn’t be ignored. Sometimes we follow orders even when we know it’s not right… and sometimes we break the rules to do what’s right.
To summarise, we improve individual SA by:
Providing Visibility
Visibility of data that impacts goals and tasks is critical, and we design to manage cognitive burden, while triggering disruption when required.Enabling Exploration
Users explore for data to maintain or regain SA as the situation changes.In both cases, Guidance may be required
Guiding the user to important but not urgent data (goal data) creates Visibility and gives Exploration a direction. A search engine (or LLM) is not the panacea; the user needs to know to look for the data, and what kind of data might be needed. Experiential led discovery alone is insufficient and inefficient.
Putting the individual components together, we have 2 reinforcing loops:
Situation Awareness & Discovery
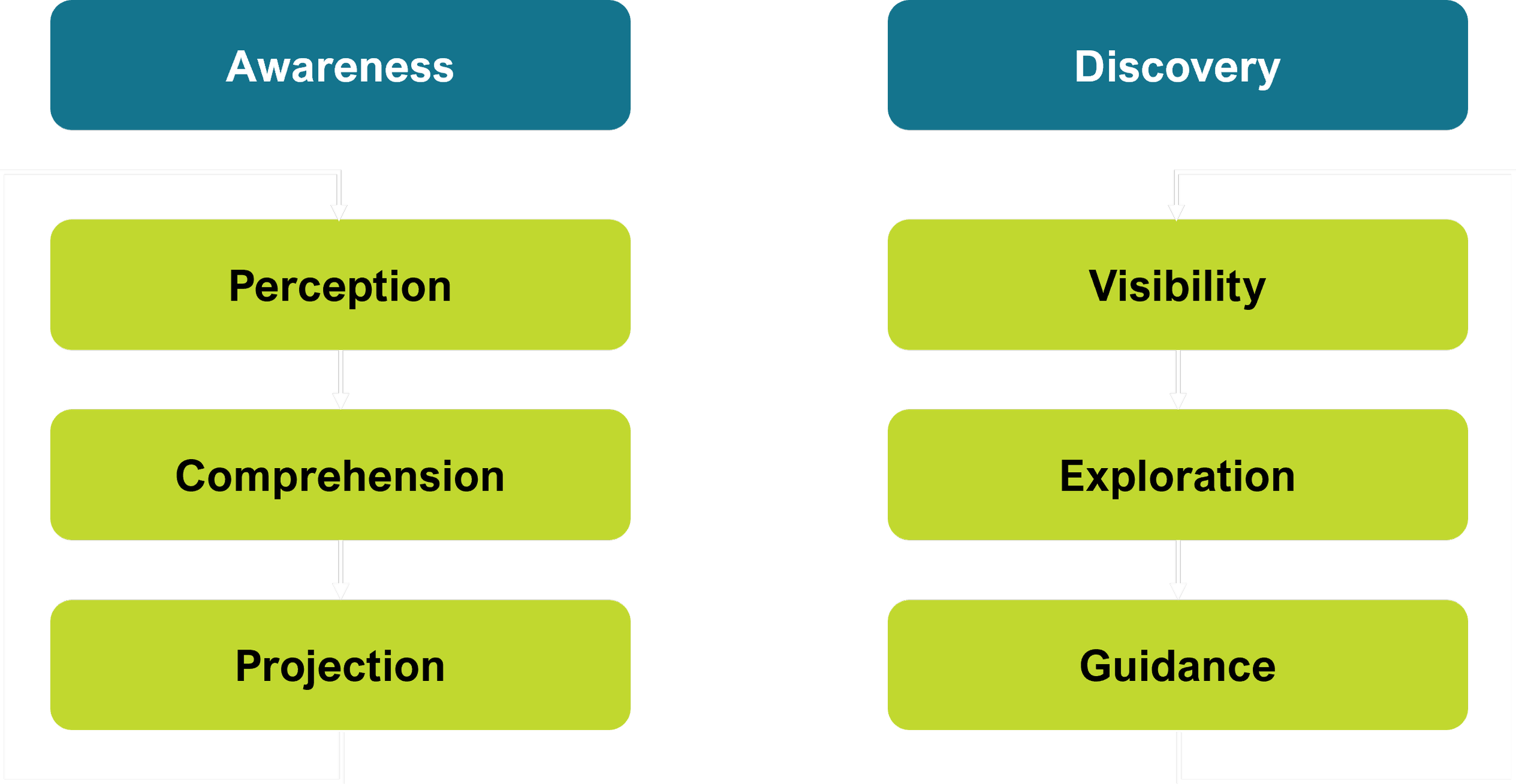
Each of these loops in turn reinforces each other. Discovery of information is informed by Goals, and this information increases Awareness.

Collaborative context creation – putting the common into COP
For industrial decision making, we have checks and balances in place, and many problems require multiple people to solve them. Shared situation awareness is more than shared observation. Interviewing 3 eye witnesses to a car accident will likely result in 3 versions of what happened, and it is possible none of the 3 versions is accurate. Remembering our description of SA, 3 observers of an unfolding issue may perceive different aspects of the situation, they may comprehend only the aspects that align to their personal experience, and from this they will naturally project different futures; the result is that 3 people can observe the same situation and determine 3 different courses of action, all based on direct observation (and hence, in their minds, “truth”).
The great enabler of industrial scale is also the great inhibitor of shared SA: Silos. From the time of Taylor and Weber we have sharpened the craft and extended it to software; silos buy siloed software, in a Conway twist. The impact on SA is obvious: when a siloed user sees siloed data, they form siloed SA, which informs siloed decisions, which have non-siloed impacts. To fight this we created dashboards to fuse data, and engineers live in excel to assemble disparate data in a way that speaks to them. The intent was sound and a great first step to de-silofication (I love that the MS Word suggestion for this non-word is vilification). The challenge with dashboards is less about technology and more about design; a reporting tool is siloed and designed to show the past. Frequently it’s inadvertently designed to set the silo in concrete. A customer I work with is proudly utilising 180 dashboards for monthly reviews. It has saved them much effort on monthly report generation. 180 static siloed dashboards, to replace the 100s of pages of powerpoint. It’s progress, but perhaps not scalable.
Most problematic of all, the siloed process of How to do something is usually uncorrelated with the decision of whether it should be done, and if so, When it should be done to maximise or minimise impact to the organisation. A classic example is an inspection of an operating asset. The maintenance process of how to conduct the inspection is very clear. The impact of timing on production is not so clear, while the impact on the maintenance teams schedule is very clear, and often in tension with production. Giving the maintenance scheduler more maintenance data and more guidance on maintenance processes does not necessarily help limit or trade-off the impact on production or operating cost. Only data that is related to the non-maintenance impacts of maintenance work provides the tradeoff for improving global outcomes, but this data is ignored if it is not part of the user’s business process. In other words, data that is siloed rarely provides context at all. Greater fidelity of siloed data is not greater context. And developing a Common Operating Picture of the users organisational silo is likely to lock that user (human or machine) into optimising for their local silo; siloed context leads to local optimisation. To overcome silos, professionals collaborate, typically outside of their systems and beside their processes.
To create shared SA, there are stages synonymous with individual SA
First comes visibility.
In a shared context however, especially when one user is showing another user their “screen”, one user’s visibility is the other users awareness. The 2nd user becomes aware of what is visible, and immediately begins situating themselves. The user doesn’t carefully review all the data on the screen before “kicking off” SA - the perceive-comprehend-project-perceive-comprehend-explore-perceive… is kicked off immediately. If you’ve ever seen those heatmap patterns of how people read websites or training material you have seen this. We start at a point and work outwards and downwards and back up and then down and back… eye tracking charts make for some interesting viewing. But don’t interpret this as “seeing” – the user is situating themselves and iteratively drawing conclusions based on the first chunks of data parsed. This is why they bang on about hooking attention in the first few words/seconds. The human SA loop is fast and continuous and involves projection, not just seeing. This then is the first step in collaboration - joint awareness. For 2 users to comprehend a common picture they must first jointly become aware of the situation as it stands, based on the data available, and then they must exchange information to validate each others SA. When we discuss an issue, we are vacillating between explaining our SA vs trying to understand their SA. This can often come across as defending our silo or justifying our point of view. Siloed data exacerbates this. When both users have different data that the other user hasn’t seen, the cycle starts anew on both sides. When the users reach joint awareness, they are both situated with the combined data. This doesn’t mean they agree; it means they’re now going to discover why the other persons SA is different to theirs.
Joint discovery is just that – discovery of data other than that which informed our SA.
When discovery is siloed, the cycle of SA formation can be kicked off many times. Each user brings back new information, which is newly perceived (or not), which may alter our comprehension (in ways they other user didn’t expect), changing (or not changing, much to the other user’s surprise) our projection of what will happen. Joint discovery is the discovery of data from any source, that becomes visible to all users. Jointly exploring and making visible new data allows each users’ SA to be perturbed by new data. Users definitely don’t mirror, and mirrored discovery would look like group think, and we know lack of diversity of thought impedes effective decision making. Joint discovery enhances ongoing communication if users are communicating. This quickly leads back into joint awareness, enabling further joint discovery. Joint discovery gets users to the crux of the issue faster by resetting each users SA faster. Sometimes this is hardly necessary, as the data that is visible tells the whole story. Sometimes the immediately visible data tells us nothing substantive and we need to dig to find out what’s really going on.
The final stage of collaboration is joint projection.
Each user has cycled their SA multiple times (sometimes many times over an extended period, returning to this issue many times) and embarks upon projection verbalisation. “I think this means…” “I’ve seen this before…” The test of projection is the validation of shared SA. When explaining why we think something we often “flesh out” half formed ideas that hereto before have been half formed thoughts. We’ve all experienced explaining something to someone and realising halfway through that the process of explaining has actually clarified something for ourselves. Projection is part of SA. Verbalising it often crystalises the differences between users’ SA. Joint projection does not imply same projection – it is individual projection based on joint awareness.
Users with high shared SA will understand why other users believe what they believe, and they will agree on common points of what the situation is. In all stages of collaboration, Goals (implicit & explicit) will have a significant impact on Awareness, Discovery and Projection. The maintenance manager will always be considering the impact on the upcoming shutdown (explicit), and the fatigue of the electrical team and risk this presents when projecting their involvement in the solution (implicit). The production manager will be considering the impact on next weeks swing (implicit), and the fact that 2 unplanned trips this last month have now put him in a position of not being able to meet his quarterly targets if he agrees to any kind of extension to planned downtime (explicit). The goals will heavily influence the direction of projection and discovery, and radically or mutually incompatible goals cannot be reconciled through high SA alone. The purpose of shared SA is not to reconcile local-local or local-global differences; the purpose of shared SA is to understand what is happening in areas outside our local environment that impact our goals.
We all know collaboration is “good”, and we encourage it for all of our workers. But collaboration is easier said then done, especially when everyone is working across siloed systems, and frequently remote from each other.
These 3 stages of collaboration then are:
Joint awareness
appreciating the other users point of view and SA.
Joint discovery
exploring and making visible more data that enhances everyone’s SA.Joint projection
explaining why a particular belief in future events will occur in order to clarify an individuals SA.

Putting it all together – collaboration in action
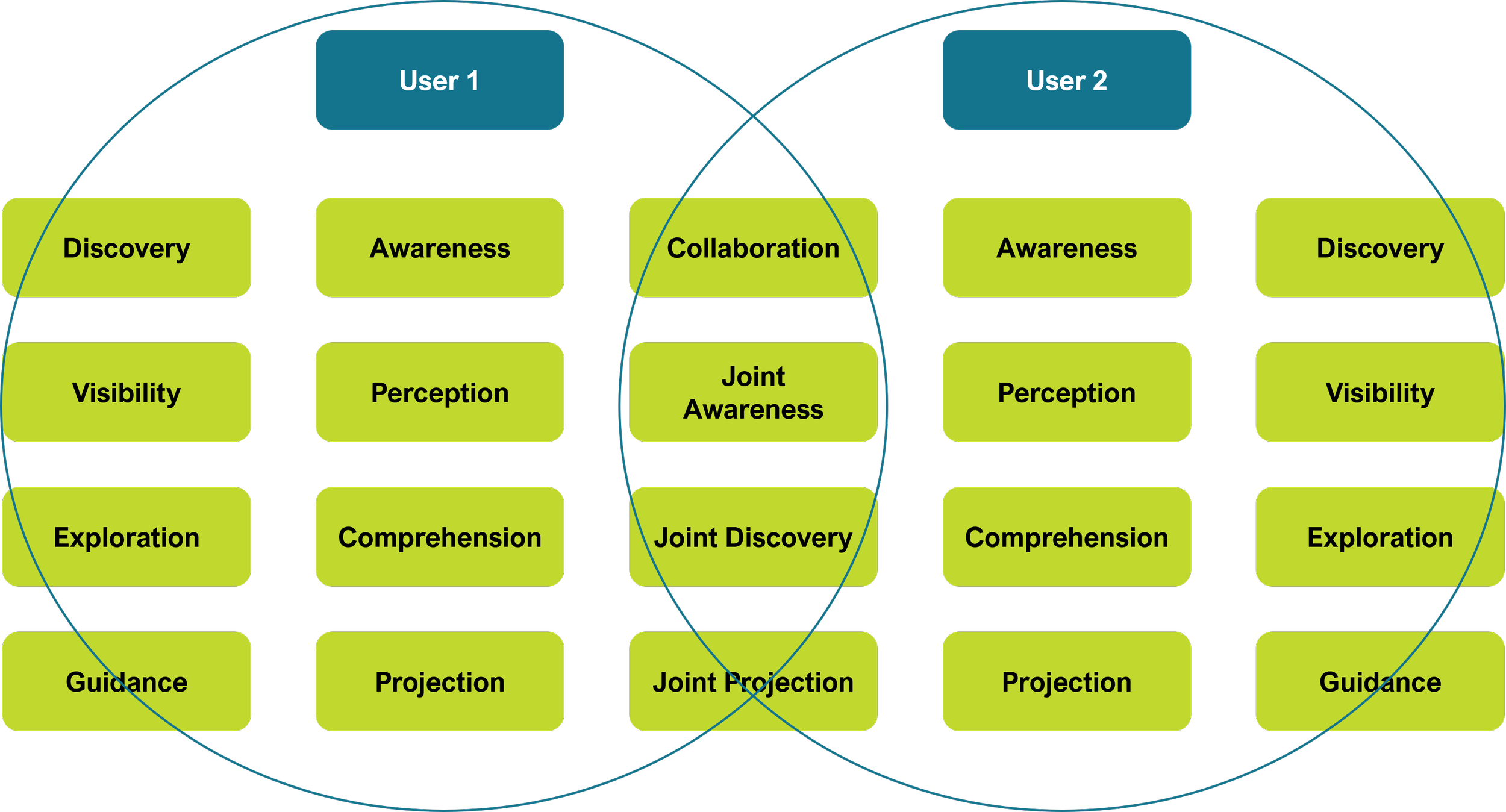
Users achieve high individual SA by raising their SA through awareness and discovery of information relevant to achieving their goals. Users create shared SA by collaborating to raise their collective understanding of the situation that impacts their goals. Collaboration drives information discovery and comparison, improving projections. Improved projections improve individual awareness, which prompts improved information discovery.
Collaboration raises shared context which raises individual SA.
Practical COP
Individual COP
To consider the elements of the COP, let us divide the problem into functional requirements. The ideal COP is the minimum data relating to the situation and the goal of the user that enables high SA. We say minimum because cognitive burden is a real thing; less of the right data is better by far than more of the wrong. In reality, it is impossible to know what the minimum is, and enabling discovery of new data is vital to improving and regaining SA as the situation changes.
Elements of the situation impact drivers of goals. Any element that impacts the goal is part of the situation, even if the user is not aware of that.
As the situation changes, the COP should change.
When the goal changes, the COP should change.
As the user discovers more information to increase SA, the COP should change.
The user should be able to change the COP based on changing situations.

In turn, let us then establish the users requirements.
As an individual COP user, I want:
the data that is relevant to my Goals to be Visible to me so that I can make decisions
to know if the Situation changes and my Goal is at risk
to know what parts of the Situation can influence my Goal
A little extrapolation of these requirements shows 2 clear modes of operation, which are very familiar to anyone in a professional setting:
Mode 1
I need to understand and manage a Situation that is or may impact Goals, and I want to know what elements of the Situation are out of order or creating risk.Mode 2
I need to achieve my Goal, and I want to know what elements of the Situation impact this.
Mode 1 is a typical supporting function such as Safety or Quality or the Control Room.
Mode 2 is a typical line of business requirement, such as Production or Maintenance.
Some users are predominantly in Mode 1 (it’s their job), until a Goal arises that requires them to manage tasks to achieve that singular Goal.
Some users are in Mode 2 by default until something goes wrong and they are thrown into Mode 1.
A good COP therefore must enable a user to operate in Mode 2(Goal) or Mode 1 (Situation), and to be able to change between them quickly, and to be able to discover information that impacts their goal or situation.
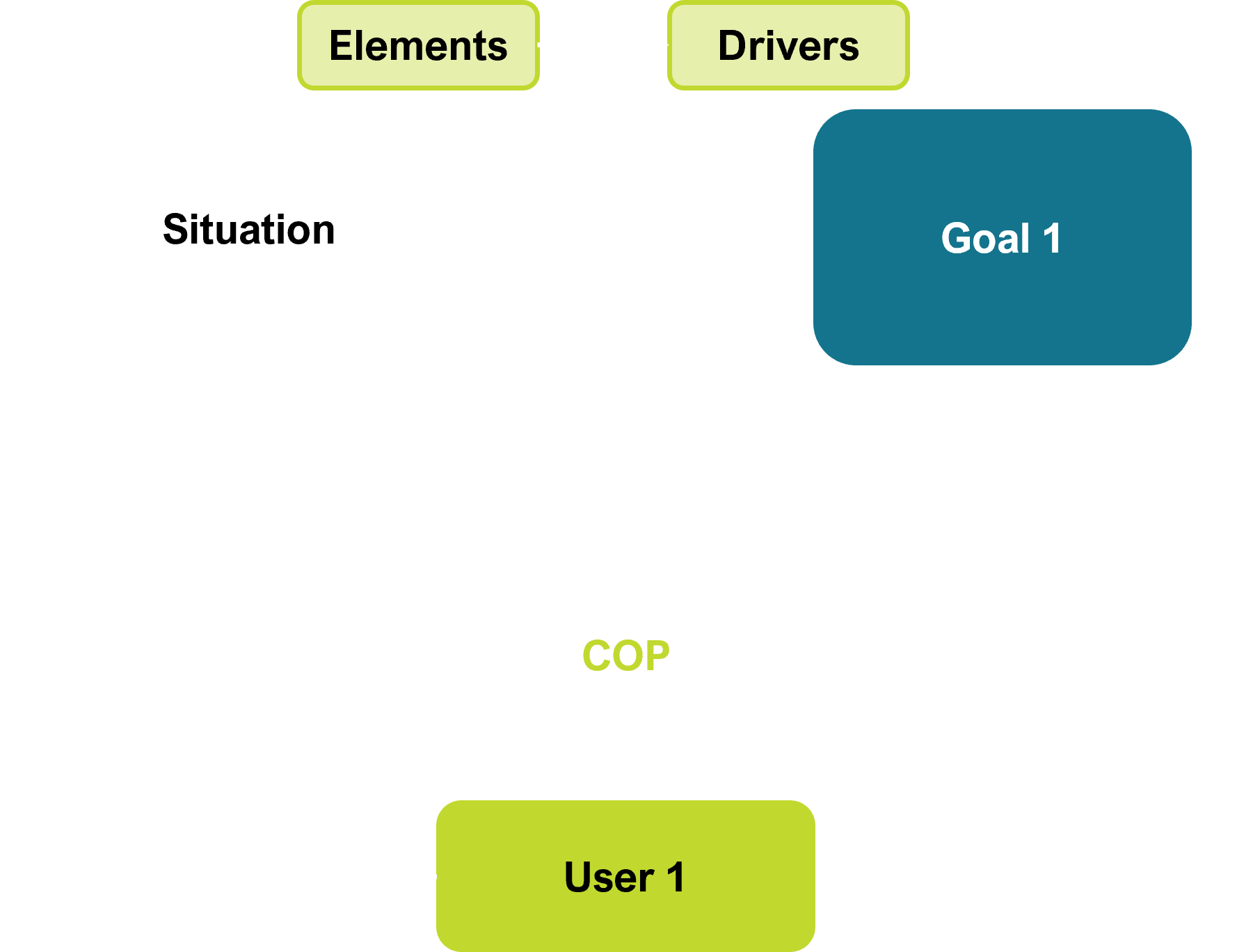
Mode 1 - Situation drives
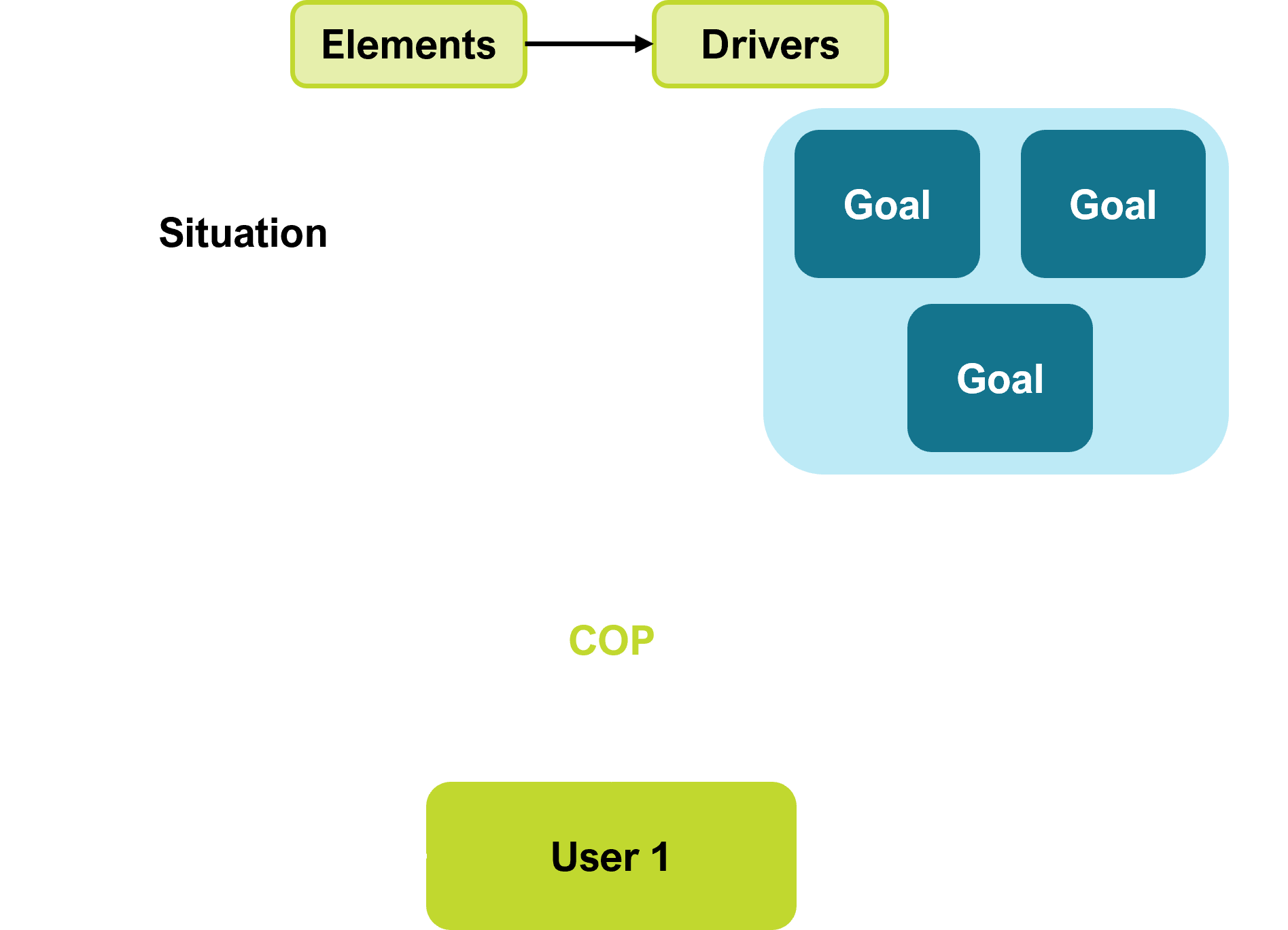
Mode 2 - Goal seeking
Shared COP
For shared context, we must consider that most goals are only achievable by a team, and that most goals can be impacted by people not in the responsible team. A truly siloed goal is a rare thing, and represents the easiest use case. At the other end, a critical business goal such as the targeted All In Sustaining Cost (AISC) can be impacted by literally hundreds of things, and there are dozens or hundreds of team goals that roll up to or impact AISC in some way. Thus the selection of what level, or area, or value driver we focus on, impacts the type and amount of information that we digest to establish SA. The simple reality of “screen real estate” has a large impact as well – we cannot and should not seek to display all the information that we can. 100 dashboards aren’t enough and are too much, simultaneously.
Similar to the individual COP, as the situation changes, the shared COP should change. When the goal changes, the shared COP should change.
As the users (plural) discover more information to increase their SA, the shared COP should be able to be changed.
This leads us to the heart of the shared COP.
As a shared COP user, I want:
to be able to share my COP with others
to be able to participate in discovery based on other peoples COP
the data that is relevant to our Goals to be Visible to us so that we can make decisions
to know if the Situation changes and our Goal is at risk
to know what parts of the Situation can influence our Goal
The first 2 requirements differentiate the shared COP from the individual. To establish, and maintain, and regain SA, we need to be able to share “our” version of reality, and we need to be able to collaborate “in” a shared version of reality. We also need to be able to launch from that shared reality and discover information, and then jointly decide if that new information improves our SA. Shared COPs need to be persistent, as collaboration can take place over days or months, and information that is useful needs to also be persistent. Each shared COP is also in Mode 1 or Mode 2 (situation or goal).
Features
We now turn to the features of a system that can deliver these requirements.
Visualisation
The beating heart of COP is visualisation. The data we perceive kicks off the SA loop. The data that changes, perturbs SA and kicks off SA loops. The data we discover needs to be viewed, and guidance on how/where to find data relevant to the situation needs to be viewed.
The technical capability of the visualisation is driven by the data types and temporal requirements of our goals. A major capital project might have multiple updates a day to CAD models, and a scan at the end of each day to update the in-progress visualisation with a point cloud. Hundreds of static documents are being created, and extensive metadata is being added and edited inside multiple models, which are then federated hourly or daily. It sounds busy, and it is.
At the other end, an operating process plant might have many thousands of sensors collecting data every 5-30 seconds. Multiple simulation and predictive data models are ingesting and running every minute, and creating transformed data that is also being stored and used as inputs to other data models, and in comparison to trends and triggers from streaming data. The static data requirements are moving slowly, but there are 30 revisions now back into history, and data still being manually entered into SAP in free text fields every hour, though sometimes days in arrears.
Both situations have their challenges, and both are present in some companies, with many variations in between. Finding the right visualisation tool(s) requires a serious assessment of what and when data is needed; the vast majority of data does not need to be real time because we do not want Mode 1 users staring at their screen, watching the world. We want them acting to achieve the goal, and then reacting well when the situation changes. For predominantly mode 2 users (e.g. safety, control room etc) we do want consistent low latency updates, but the resilience of the connection to upset elements may be more important than the turnaround time of the cloud. Even (especially) in “crisis management” mode, we are seeking the highest possible SA – not the highest fidelity/amount of data or fastest time to perception. We need to enhance SA, not just perception, to improve decision making, especially when stress levels are high.
The design of the visualisation thus becomes paramount. Not just “where” data goes, but how a user can ingest multiple data types, and be guided to critical data, and easily configure the COP to visualise, compare or contrast multiple data sources.
Mode 1 is situation directed. We have an area/location/process/asset, and many associated data types, and adjacent (space/process i.e. relationship) data that may impact the situation.
Mode 2 is goal directed. We have a goal, and many types of data may need to be shown related to the goal, while other data may (will) need to be hidden.
Every user will therefore need multiple individual COPs, some goal directed, some situation driven. Multiple COPs also reduces the cognitive load and requirement for each individual visualisation.
Each users goals and situation also needs clarification. Making a users goals clear, and visible, helps reinforce the goals that are critical to the situation and help the user to anchor their discovery in their goals.
The experience of using the visualisation is also critical. The COP aims to create improved SA for the user. A poor user experience (UX), clicking around searching for the right button, or struggling to change how data is viewed, will provide a poor experience. In SA, a poor experience is likely to slow the SA loop and add stress. Stress reduces cognitive capacity. The COP is one of the instances where we can truly say that a poor UX will reduce the value of the tool.
With so many possible forms and sources of data, and multiple “open” COPs, establishing templates for how certain kinds of data can be viewed, and how multiple types of data can be viewed together (compared, juxtaposed, spatially, temporally etc) is an essential building block. When combined with user configurability, these visualisations form the heart of the COP.
A special note on autonomous systems: while autonomy will grow quickly, there is a distinction between deciding and being aware of what decisions have been made. Prescriptive and autonomous systems will grow and many decisions will be automated, and humans will need to situate themselves quickly and regain their SA as autonomous systems operate. The need for SA in an autonomous world is likely to increase, as the number of humans decreases and the number of decisions made multiplies exponentially.
SA will be a key enabler of autonomy as it enhances the human ability to encompass algorithmic decision making at scale.
Discovery
To inform our SA and validate our projections, we need to discover more information. The 3 steps of Discovery are Visibility, Exploration and Guidance. We also have 2 modes of Discovery, Situation (Mode 1) and Goal (Mode 2).
Visibility is related to Visualisation, but also extends to making connected data visible. The COP is connected to many systems, and most of these systems have specific data and functionality in them that is valuable. Making connected systems and data available and accessible helps the user discover and explore. We want the user to use that unique human superpower to “jump” to where they think answers lie.
Visibility also relates to bringing data back to the COP. For the individual, we wish to juxtapose new data with old. For the shared COP, we wish to make visible the data we have explored for collaborators to review and learn from. In all cases, “bringing back what you’ve learned” is key, and one of the key differentiators of a true COP from a dashboard.
Remember, we increase SA by discovering additional relevant data.
Projection
Enabling projection enables the user to validate or invalidate assumptions about the present. The mental picture of what is happening is truly tested by the projection of what will happen next. In shared COPs in particular, projection checking is one of the most valuable tools for checking shared comprehension. Most projection tools are essentially convergent tools – i.e. they direct attention in accordance with structured inputs, and do not (cannot) include external stimuli or data. Experienced based logical assessments also fall into this category, where inputs and options are eliminated in order to narrow down focus to a few “probable” scenarios. Convergent thinking is necessary to reduce cognitive burden, at the risk of eliminating potential outcomes.
Projection tools fall into 5 main categories:
Logical models
Algorithmic models including Predictions (subtype of algorithmic)
Simulations
Plans
Assessments
Logical models such as value driver trees create logical links between outcomes or activities, to create logical chains. Examples of logical models include If-then and constraints models. Logical models can provide directional as well as numerical projection. One of the key benefits of logical models is that they often align to or are the basis of KPIs and rollup of KPIs and metrics. Projection testing of metrics helps to benchmark potential consequences, and directional projection helps to narrow the guidance for discovery.
Algorithmic models encompass numerical methods for projection, taking inputs and returning outputs. Predictive models and modern ML methods introduce learning models, that can be trained on data and produce higher probability predictions that logic or fixed algorithms alone. ML methods also encompass analysis, and analytical models often inform predictive models. Value chain optimisations are a good example of combined analytical and predictive models. Co-pilots and agents are generalised models that can operate across external data sources as well as their foundational data sets.
Most simulations can be thought of as a class of algorithmic model, however some simulations are in fact logical visualisations, crafted by expertise and logic to simulate a possible future event. As such some simulations are scenario builders, rather than first principle simulations. The development of multi-physics simulations is opening the field for genuine first principles projection, and as a project testing and scenario tool they may hold greater value than as a detailed planning tool, as the limitations of models are still very real. Simulation of a bridge design, for example, does not (at this stage) remove the need to design the bridge from well understood (and somewhat heuristic) engineering principles, nor does it obviate the need to check said design against standards, and for a qualified person to sign off the design. Projection to test or ideate scenarios is currently a far easier class of problem, and still very useful to SA type projections.
Plans also provide a type of projection check, whereupon the projected future is compared to the plan in order to understand potential deviation. Plans can anchor thinking by converging possible outcomes to what we thought should happen, but they can also give concrete examples of goals that are in jeopardy, which assists with goal directed SA.
A final special mention is situated reasoning, where possibles rather than probables are calculated or inferred based on situations, relationships and potential chains of causality. This field has great potential to negate premature convergence and unlock projections and checking that is beyond the compass of human cognition.
Guidance
Inside a complex organisation, a random search to increase SA is unlikely to be efficient enough, though experience will inform and guide experienced users to data that fits their mental models. We also wish to expose data that has a high probability of being related to the goal or situation.
Guidance can take many forms, and most or all have a place in a COP:
Relationships
Rules
Search
NLP informed Search & Discovery
Relationships are structured semantic or other relationships between data. Metadata informs many relationships, and graph and vector databases are built on relationships. Data models incorporate many relationships between data, and utilising models to inform relationships is a key factor, especially when consider goals. Examples include value drive trees, constraint models, and value chain optimisation models. Creating explicit links between value drivers enables rapid discovery of elements impacting goals, and reverse engineering to goals impacted by elements.
Rules utilise relationships, metadata and triggers from data to perform workflows. Rules engine abound, and rules engines give the ability to create rules that guide users. Rules can also drive triggers and notifications, which are critical to raising hidden data into the Visible compass of the Visualisation.
Search similarly utilise metadata and data, and search can cross as many parameters as the user can architect can conceive. Search alone though can be very frustrating, especially with heavy duplicate or dirty data or data buried in siloed systems. Search is not yet a panacea, though intelligent search is becoming more powerful every day.
The advancement on search is of course AI, and natural language processing (NLP) in particular through the likes of ChatGPT. AI based search, and searches that learn, are becoming prevalent and it is possible to both build, tune or white label intelligent search options and recommendation engines.
In all cases, the investment in discovery and guidance will pay off, arguably more so than Visualisation alone. Humans are thirsty creatures, and discovery of data is both the thirst quencher and the preventative measure of dashboarditis.
Connections
A COP is a connected system. It creates value by connecting users to the right data at the right time. Connected systems are becoming more common place, and connecting multiple data types is critical. While data lakes are becoming very commonplace, the need to enable discovery and utilise functionality within data silos may necessitate direct connections to critical systems.
Collaboration, Sharing & Persistence
Users benefit from communicating while observing the same visualisation. Being able to share visualisations, and collaborate remotely on another users visualisation, is therefore a key enabler of shared COP. Capabilities such as IM (e.g. the company preferred channel such as Teams or Slack) should be part of any shared COP. These visualisations must also be easily shareable, and persistent in the sense of once configured, they can remain in place and be updated as data changes, and any triggers will notify the user, even if they are on a different COP or in a different system altogether.
An additional benefit in this day of post-COVID remote support and collaboration is being able to invite in non-domain users to view specific visualisations, with appropriate read/write and filtering/search permissions. External experts bring diversity of thought, and their SA loop will almost always include different projections and a desire to discover more or different information.
Organisations and teams within organisation establish patterns and rhythms that serve the team well. To introduce a COP into a business, the COP will need to be able to change and adapt as the team learns what templates of UI work, what data sources are commonly needed, and what data is regularly sourced for given situations.
Machines will increasingly play a more important part in helping humans situate and decide, as raw data is played through models and transformed data enters the human SA loop. All organisations will advance along this continuum to some extent, and as co-pilot / agents advance, “intelligent” assistants will become part of collaboration loops.
Summary of features
Let’s summarise the features of the system that provides individual and shared COP.
Visualisation
The core of COP, driven by data types, frequency, fidelity and resilience: SA >> perception.
UI and UX are critical.
Goals are visible and the situation can be viewed from multiple points of view.
Algorithmic/machine decisions need to enable the user to maintain SA or quickly regain it in the event of major disruption.
Multiple visualisations make up an individual COP.
Visualisations are configurable by the user, and templates for common situations and goal types are provided.
Projection
Users can project manually and discover, or use tools such as models and simulations to extrapolate from current situations, or to test scenarios of adjusted situations, or to examine plans and goal drivers.
Discovery
Users can explore data that is available in connected systems, in situation or goal directed behaviour.
Search is one tool, and intelligent (e.g. NLP/chat) search tools will be invaluable across large and disparate data sets, with appropriate constraints and governance.
Users can link and/or visualise connected data in the COP.
Guidance
The system can guide the user to perform discovery and find information relevant to goals and the situation. Guidance enhances discovery, especially inside complex systems with many hundreds of potential data sources.
Relationship tools such as knowledge graphs can be invaluable for creating semantic relationships that the user can easily explore or search.
Connection
A COP is a connected system. Connected data underpins the visualisation, but it is also essential to discovery. Being able to easily and quickly explore and dive deep enables SA.
Collaboration
Visualisations and discovered data are easily shareable.
Visualisations are persistent and update regularly even when not in use.
Users can chat with users and machines and the chat is persistent with the COP.
Users can notify users who are within or external to system (email, text, IM etc).
A worked example of the main features in action
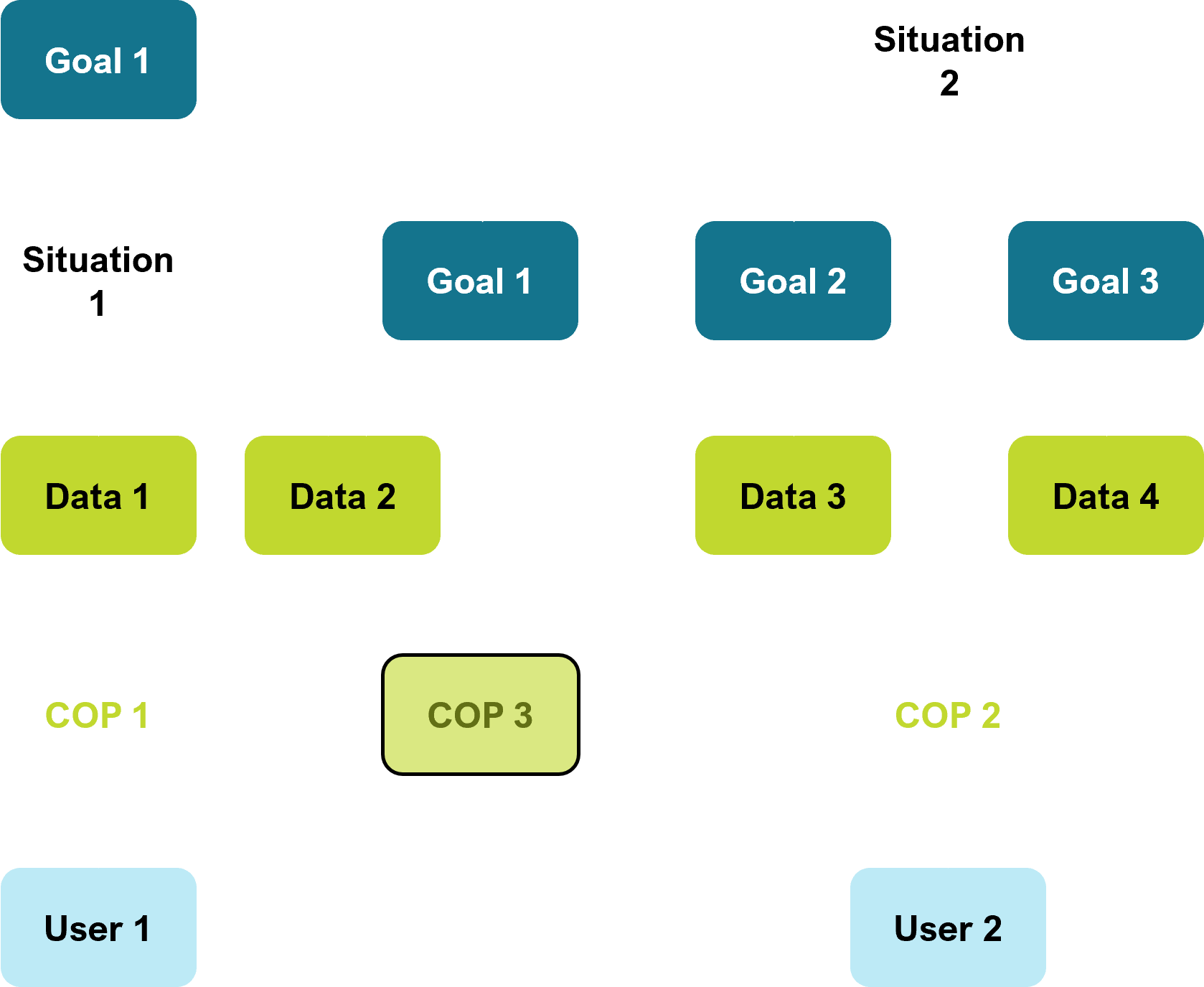
Goals & Situations drive Data requirements, determined by Relationships and enabled by Connections
User 1 is viewing COP 1, driven by Goal 1 and Situation 1
User 2 is viewing CO P2, driven by Situation 2 and Goals 2 & 3
COP 3 is created by User 2, because Goal 1 impacts have been notified. User 2 invites User 1 to share COP3.

User 1 views COP 3, and performs Discovery to gain SA on Situation 2, and projects on Goal 1. User 1 wants to understand what Situation 2 means for Goal 1.
User 1 & 2 now Collaborate on COP 3. Both users still have access to and are using COP 1 & 2 as required. COP 3 is persistent until no longer required.

User 3 is invited into COP 3, gains SA, and immediately begins Discovery in Data 5, a connected but not visualised system, based on User 3s experience.
Users 1, 2 & 3 Collaborate with User 3s Discovery, and User 2 requests connection of Data 5 to COP 3 to enhance SA.
COP 3 is now the shared COP for Users 1, 2 & 3 related to Situation 2.
Users 1 & 2 still have their individual SAs for managing their other situations and goals.
The cycle continues, with the real world changing, goals and situations changing, and users gaining and regaining SA through discovery and collaboration.
The Digital Twin
Where do digital twins fit into all this?
We began with describing the flow of activity from changes in the real world to action. While we have focused on the Common Operating Picture as the critical enabler of SA, and we have shown that SA is valuable in and of itself, the primary value of SA is to enhance decision making. Decisions drive actions, and actions create change in the real world, which necessitates regaining SA, in order to make decisions… The digital twin wraps up the end to end of change and action.

Digital twin definition
A digital twin comprises a virtual representation of a selected portion of the physical world, with two way interconnections, synchronized at specified frequencies and fidelities, and designed to create change in the physical that can be measured and improved in the virtual.
Digital twins codify continuous improvement of assets, systems and processes. They are purpose built to operate across assets, systems and organisational silos, with historic, near real time and predictive data. They improve decision making by providing people with the right data to make the right decision at the right time, and speeding up how quickly we learn from those decisions.
What is the difference between a COP and a digital twin?
COPs ingest data, and help humans make sense of it, so that humans make better decisions.
Digital twins ingest data, help humans and machines make sense of it, so that humans and machines make better decisions, and tracks and learns from the decisions, actions and real world changes.
Let’s go through the specific features of a digital twin that differ from or are added to a COP.
Visualisation
With the inclusion of decisions, via user actions that create change, the COP can now include decisions to further enhance SA. We often project far beyond the very next action, and certainly beyond the next decision, and so a rearrangement of the decision cycle might look more like this:

We project beyond the next step, and then take the next step, and then the changes in the real world “catch up” to what we projected may happen. The consequences of decisions are, therefore, a kind of check on our projection. As we saw with projection aids such as simulations and models, checking projections aids SA. Thus the inclusion of decision visibility aids SA, and the ability to track decisions provides the underlying data for learning about how and how well we make decisions.
Similarly, where decisions become increasingly automated, the digital twin can track machine decisions and actions and can make the users aware of them inside the COP. As more decisions become human-out-of-the-loop, the human user faces a situation of potentially decreasing SA. Visualising automated decisions helps user regain SA faster.
Situation Twins, designed to encompass both “visualisations” as well as every other type of data
2 way connections
A digital twin creates decisions and actions, and both are often translated into the real world through systems such as EAMs or CMMS. Not all connected systems need 2-way connections, but the ones that create action in the real world, and are related to the use cases the digital twin was designed for, do. Work, such as maintenance or shutdowns, is a perfect example of non-physical world data that is ingested in the digital twin. The work done on and around the part of the world or process we are interested in is critical to understanding what is happening and why. This also applies to control of the physical world, wherein a digital twin that is directly connected to equipment/valves/actuators/other digital twins can create direct outcomes in the real world, without humans as the intermediaries. In both cases, strong connection to outcomes should be linked back to what is measured by the twin.
Learning
Digital twins encompass the real world-decision-action cycle, and as such the tracking and storage of changing inputs, user actions (that correspond to decisions) and user actions that correspond to actions (through connected systems and people) are tracked. The tracking of this lifecycle creates the opportunity to analyse and improve how we make decisions and what decisions we make. Importantly, we not only learn from human decisions (the critical case of change in the real world that was perceived but not acted upon), but we enable learning from machine decisions and human-machine collaboration. With the ever increasing rise of predictive tools, enabling learning across human-machine air gaps may be one of the most valuable tools we can deploy.
Feedback & Control
The follow on to learning and machine decisions is feedback and control. Many decisions can be taken outside any connected system; the radio and Whatsapp are perhaps the most vital communication channels for decisions on many sites. Creating the ability to easily feedback on decisions where action is taken outside any connected system enables a measure of learning loop that goes beyond integrations. Perhaps needless to say, the user experience needs to be enhanced by this feature, not made worse, or feedback can be expected to be nil or n/a. Feedback learning helps put quantitative learning in context, and should improve templating, configurability and guidance. Where machine decisions are increasingly being made, an ounce of control may also be beneficial, to enable users to intervene or at least flag machine decisions that the user disagrees with. Where a clear conflict or risk is exposed in the COP, something as simple as making it easy to take screen shots or invite a user into a COP to view the risk can help the machine trainer enhance their SA, hopefully leading to improvements in algorithm or governance.
Wide vs Narrow
Perhaps the most important differentiation of a COP vs a digital twin is that a COP is built to encompass situations and goals, while a twin is designed to solve problems. Without resorting to semantics, the difference is a case of focus. COPs must be wide and must be able to go wide, so that the user can discover the information they need to enhance or regain their SA. Go wide to find. Digital twins are designed to create change in the real world, and so they start from deliberate, desired change and work backwards to capabilities. Focus to solve. In practice this means a COP is likely to have 20 data sources connected, and all of them 1 way, while a twin use case may only need 4 of those data sources, all 2 way, and the application for action on that use case will be more comprehensive and specific. A COP to rule them all, perhaps, and digital twin capabilities to create the pathways to collaborative courses of action. In practice, a world of COPs inside a digital twin is easily accomplished, while adding a digital twin to a COP may be very difficult. A COP digital twin makes a lot of sense.
| Feature | COP | Digital Twin |
|---|---|---|
| Visualisation | Y | Y |
| Connection | Y (1 way) | Y (2 way) |
| Relationship | Y | Y |
| Discovery | Y | Y |
| Collaboration | Y | Y |
| Projection | Y | Y |
| Learning | N | Y |
| Feedback & Control | N | Y |
| Wide vs Narrow | Wide | Narrow/Wide |
Summary
As we have seen, COPs are far more than an emergency response tool. Situation Awareness enhances decision making, and humans rely more on goals than tasks to gain and regain SA. In modern organisations, our people mostly work collaboratively on goals and they spend most of their time focusing on achieving goals. A small section of our workforce focuses on situations, and all humans need to situate and adapt to changing situations as they arise. Moving from mode to mode, and multi-mode management, are the norm now. COPs should enable individual and collaborative goal directed and situation driven SA.
Digital twins provide a method for taking this enhanced and collaborative SA and turning it into structured decisions and action through connected systems and data. By converting human decisions and actions into structured data, we can enable learning across value chains and collective human/machine decisions. By including machine decisions inside our SA loops, we can provide humans with the tools to collaborate with machines and to operate alongside machines without degrading their SA. More intelligent discovery through AI and transformers will enable more effective use of the data we collect, and capturing human “jumps” from goal or situation to (seemingly) non-related data source will help inform successive generations of learning on how humans really make decisions and solve problems.
A digital twin can encompass and deliver COPs - and provide directed connections and learning to a level far beyond a COP. A digital twin therefore can deliver COPs, and connect the decisions made from within COPs to the real world. Many COPs within a twin, and iteratively greater connections of COPs to action in the real world.
In future orks we will detail the methodology for designing a digital twin that provides a shared COP and solves specific problems within the organisation. Digital twin design is holistic, and by working backwards from real world problems, we can design a virtual tool that helps users solve real problems.
Author’s Note
Thanks for reading! If you made it this far then I’d love your feedback, or if you want to have a vigorous philosophical debate then buy me a coffee and put your dancing shoes on. You can contact me on rob@geminum.co or through my linkedin.